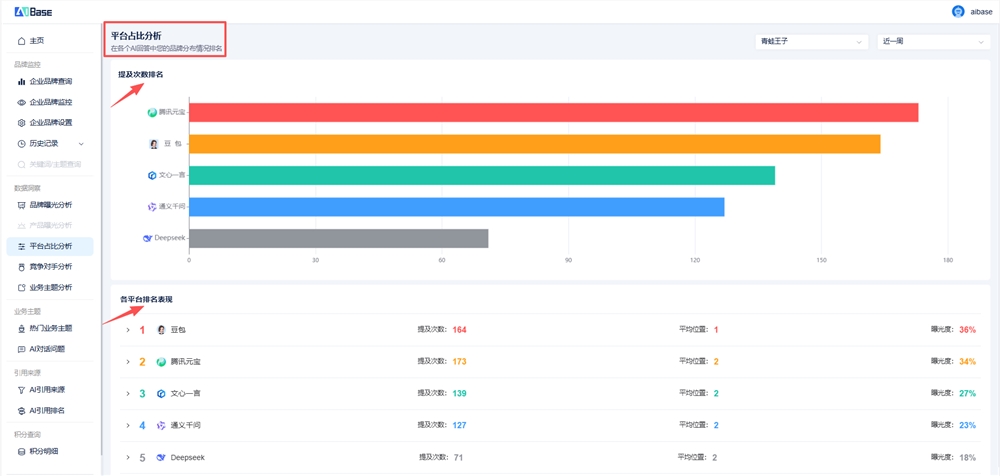
OpenAI 近期对 Evals 工具进行了重大升级,新增了原生音频输入与音频评分功能,为开发者带来了革命性的评估体验。这一突破性更新允许用户直接对模型的音频输出进行评估,无需经过繁琐的文本转录环节。新功能显著简化了语音识别和语音生成模型的测试流程,大幅提升了开发效率。借助 Evals 的原生音频支持,开发者能够更精准地测试和优化其音频应用性能。用户只需上传音频文件,即可在平台上实时获取性能评估结果,不仅大幅降低了数据处理难度,更提高了评估结果的准确性和可靠性。对于需要频繁迭代音频模型的开发者来说,这一功能无疑是一剂强心针。该功能的应用前景广阔,涵盖了智能语音助手开发、语音识别系统性能测试、音频内容生成质量监控等多个领域。此次更新为开发者提供了更直接、更高效的评估工具,助力其打造出兼具高质量和高性能的音频应用。更多详情请访问:https://cookbook.openai.com/examples/evaluation/use-cases/evalsapi_audio_inputs