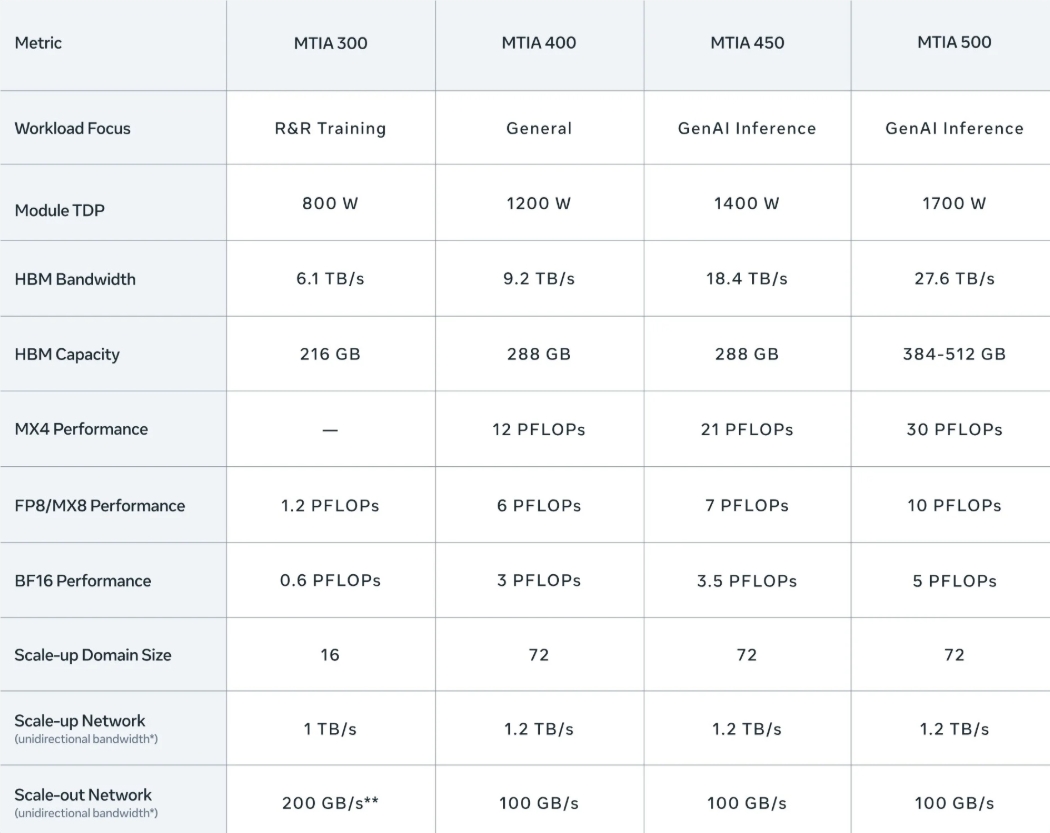
微新创想:在 AI 浪潮重塑商业逻辑的今天 青岛走在了全国前列
3 月 11 日 青岛首支专注“单人+AI”创业的科创基金——青岛超级个体科技创业投资基金正式完成工商注册 这不仅是一次金融尝试 更是对未来“一人公司”商业形态的深度布局
精准“滴灌”:5 万也能开启 AI 创业 区别于传统创投动辄数千万的大手笔 该基金展现了极高的灵活性与包容性 由春峰里资本与柠檬豆联合发起的这支基金 首期规模为 5000 万元 其核心亮点在于采取了“5 万至 50 万元”的小额精准投资策略 旨在通过极低的门槛 帮助那些拥有技术或创意 能熟练驾驭 AI 工具的“超级个体”快速起步
七大赛道:AIGC 成为创新主阵地 目前 该基金已储备首批投资项目 精准锁定在 AIGC 内容创作等七大细分领域 这些项目普遍具备“轻资产、高人效、强 AI 依赖”的特征 配合青岛市同步推出的 OPC(One Person Company 单人公司)扶持政策 创业者将获得从资金到政策的全方位护航
“未来之星”行动:三年培育百个优质项目 与基金成立同步启动的还有“OPC 未来之星 100 行动” 该计划为入选项目提供了包括房租减免 算力补贴 技术支持在内的八大扶持政策 目标是在未来三年内 在青岛本土培育出 100 个优质的“单人+AI”示范项目 构建起一个充满活力的超级个体创业生态体系
商业新形态:AI 让“单兵作战”成为可能 青岛此举释放了一个强烈信号 在 AI 时代 一个人 一套 AI 工具 一份精准的投资 就足以构建一家极具竞争力的企业 这种“单人+AI”的 OPC 模式 正打破传统企业的组织边界 随着青岛超级个体科技创业投资基金的运行 青岛有望成为国内 AI 创业者的首选栖息地 引领新一轮的数字化创业热潮