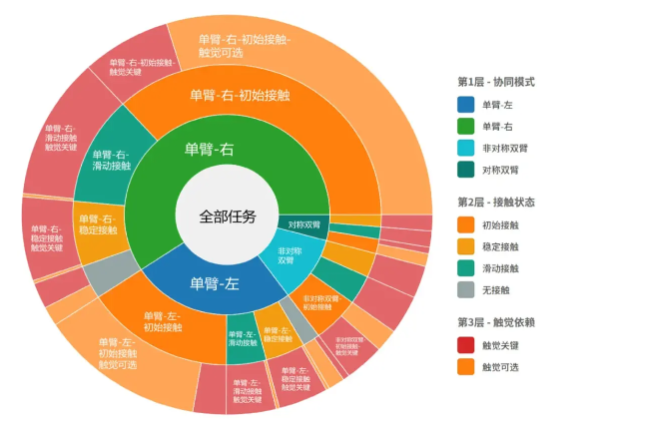
1月24日,领先的训练数据公司Mercor发布了一份重磅研究报告,揭示了主流人工智能模型在真实办公环境下的实际表现。该研究采用创新的基准测试APEX-Agents,通过模拟律师、顾问等专业人士的工作流程,评估AI模型在处理跨邮件、PDF文档、电子表格等多源信息协同任务时的准确率。结果显示,尽管AI技术在不断进步,但在复杂多步骤任务中的准确率最高仅为24%。
在此次测试中,Gemini 3 Flash与GPT-5.2表现相对突出,分别位列前两位,但其准确率均未超过25%。值得注意的是,大多数AI模型的准确率都徘徊在20%以下,这表明当前AI技术在实际办公场景中的应用仍面临诸多挑战。
Mercor首席执行官在报告中指出,AI模型在上下文整合能力方面存在明显短板,往往容易混淆任务细节或轻易放弃复杂任务,导致整体表现不尽如人意。他形象地将目前的AI水平比喻为“不可靠的实习生”,虽然能够完成一些基础工作,但难以胜任需要深度思考和知识整合的复杂任务。
与一年前5%-10%的准确率相比,AI在办公场景中的表现确实取得了显著进步。然而,这一提升距离真正胜任复杂知识工作仍存在明显差距。Mercor的这份报告不仅揭示了AI技术的现状,也为未来AI模型的优化方向提供了重要参考。随着技术的不断迭代,我们有理由相信,AI将在未来办公场景中发挥越来越重要的作用,但实现这一目标仍需时日和持续的努力。